
Работа с семантикой не ограничивается сбором ключевых слов из «Вордстата» с оценкой частотности и последующей кластеризацией. Это лишь старт рабочего процесса: вы должны понять, что хотели люди, обратившиеся с этим запросом к поиску, и как сделать так, чтобы поисковые системы показали этим людям именно ваш сайт.
57 показов 21 открытие

Контекст – это совокупность связанных объектов, влияющая на понимание любой части этой совокупности. Контекстный поиск — это поиск с учетом разных контекстов одних и тех же запросов. Один и тот же запрос может соответствовать множеству постоянно изменяющихся контекстов и намерений (интентов) пользователя, обратившегося к поиску с этим запросом.
Ещё раз о типах запросов
В 2002 Андрей Бродер предложил классификацию поисковых запросов, теперь известную каждому:
- Навигационные: пользователь ищет вполне конкретный сайт. Он там уже бывал или уверен, что такой сайт есть. Чаще всего такой поиск подразумевает единственный («витальный») результат.
- Информационные: поиск информации, которая может быть размещена на нескольких разных веб-страницах в статической форме. Подразумевается только чтение, никаких больше взаимодействий со страницей.
- Транзакционные: подразумевается выполнение какого-то действия в рамках веб. Покупка, обращение к веб-сервису, скачивание файла, обращение к базе данных. Неправильно считать транзакционные запросы «коммерческими», поскольку речь о любой интерактивности.
К этому списку в 2006 в документации Google были добавлены ещё локальные запросы, при которых пользователь ищет какие-то местные компании.
Контекстный поиск замещает синтаксический
И вот ещё недавно мы смело делили все ключи на коммерческие и информационные, старались получить первые позиции в топе поисковой выдачи. Кажется, эта система перестала работать:
- Топы устойчиво занимают маркетплейсы, способные по историческим данным поисковиков закрыть максимум возможных намерений пользователя в выбранной тематике;
- Выдача меняется при каждом обновлении страницы: вот ты – первый, вот – восьмой, а вот ты уже вылетел за пределы топ-10;
- По наиболее частотным запросам выдачу занимают очень разноплановые сайты: можно быть вторым в своей сфере, и занимать при этом позиции за пределами топ-10;
- Предельно точная оптимизация средствами синтаксиса (вхождения) под чётко сформулированный запрос может ничего не давать: поисковые системы всё равно переформулируют («переколдуют») запрос и отбросят все ваши уточняющие слова.
Ларчик открывается просто: поисковые системы накопили достаточно большие объёмы информации как по запросам, так и по аудитории, и в обработке запроса учитывают самые разные цели поиска на основе контекстов. Они знают, что именно вы искали, что искали до этого, что искали и как реагировали на выдачу другие люди, похожие на вас. А значит, релевантность в конкретном временном срезе определяется в том числе и контекстом конкретного документа и источника – в том числе и в исторической перспективе. Вы можете писать очень интересные, полезные, экспертные статьи, но если у поисковой системы нет никаких данных о взаимодействии пользователей с вашим сайтом, это не даст ровным счётом ничего.
Единой неизменной выдачи по более-менее частотным запросам больше нет. Результаты персонализируются, и чёткая система здесь не прослеживается. Помните шутку Деваки про «SEO-амулеты»? Сейчас вам могут показывать сайты, на которые вы уже заходили не раз. А могут их скрывать – если поисковик сочтёт, что вы не добились результатов на этих сайтах. А если Яндекс не увидит соответствия запроса вашему профилю – будете разгадывать капчу.
Главные условия для получения высоких позиций в рамках контекстно-семантического поиска можно сформулировать так:
- Поисковая система должна понимать запросы. Для этого совершенно недостаточно использовать синтаксические методы (наличие каких-то ключевых слов, их частотность и т.п.).
- Продвигаемая страница должна соответствовать пользовательскому намерению – тому, ради чего и обращаются к поиску.
- У поисковой системы должна быть накоплена какая-то статистика по запросам и пользовательским сигналам в рамках взаимодействия с поисковой выдачей и сайтами по этим запросам.
Что определяет персонализацию
Фактически – всё, что поисковая система знает о пользователе и актуальном временном срезе:
- Устройство
- Локация (в зависимости от региона – вплоть до улицы)
- Время суток
- Дата
- Демографические данные (пол, возраст)
- История поиска и посещенных сайтов
- Долгосрочные интересы пользователя в исторической перспективе
- История взаимодействия пользователя с бизнесами (посещенные магазины, оставленные отзывы)
- Оценка тона голоса (если речь о голосовом поиске и взаимодействии с устройствами)
и т.д. И это только на стороне пользователя – и в основном такое, что никогда не просчитывается в рамках оптимизации. Вы хоть раз пытались оптимизировать свою посадочную страницу для человека, который нашёл ваш сайт будучи за рулём, уставший после тяжелого дня, или на ходу на тёмной улице, во время снегопада?
Мы чаще всего исходим из того, что по ту сторону дисплея – трезвый и собранный человек в офисе. Но даже если он в офисе за большим монитором – его могут дёргать с трёх сторон, и уже надо бежать на обед. А вы ему – тонны ненужной информации с хорошо запрятанной важной. Зато ключевые слова – проработаны, 40 прямых вхождений и 100 словоформ.
Не надо думать, что ПС будет формировать выдачу специально для вас из всех сотен тысяч соответствующих страниц. Ингредиенты всё равно останутся теми же самыми, просто приоритеты будут меняться.
Алгоритмы контекстного поиска сейчас используют и Гугл, и Яндекс, поэтому если вы всё ещё зацикливаетесь на ключевых словах из запроса и лексическом сходстве – вы застряли в прошлом. Да, оно всё ещё живо: поисковые алгоритмы достраиваются, ничто не исчезает абсолютно. Но полноценная оптимизация подразумевает учёт и объединение всех значимых факторов, влияющих на ранжирование. Современная работа с семантикой подразумевает контекст. И работа с контекстом выходит далеко за рамки мифического “LSI”, правой колонки “Вордстат” и блока «Вместе с этим ищут».
Что нужно для оптимизации контекста
Классический подход для проработки контекста/интента подразумевает уже упомянутую классификацию, где все запросы рассматриваются как коммерческие, информационные, навигационные, локальный поиск и т.п. Этот подход остаётся практичным, но он слишком груб и упрощён. Случайный поиск уровня «это что» может состоять из единственного запроса, для которого достаточно будет блока прямо на выдаче. Чаще же речь идёт о цепочке уточняющих запросов, которые поисковая система рано или поздно сможет связать в чёткий шаблон и выявить стандартные паттерны, связывающие запрос, аудиторию, историю посещений и т.п. Всё это станет частью атрибутов некоторой поисковой сущности и связанных с ней узлов семантического графа. Полученная таким образом классификация будет много более сложной, чем просто «это что» – «купить» – «проложить маршрут».
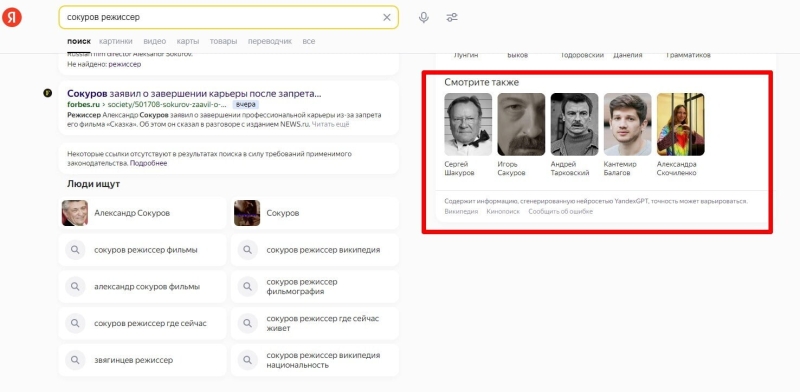
В данном случае Яндекс связал Сокурова, Сакурова, Шокурова, добавил пару режиссёров и “жертву режима”. Полный набор толстых намеков об объекте поиска.
Существует класс симптоматических запросов: информационных по сути, но необходимых для выполнения транзакции. Пример: перед «чёрной пятницей» тесть попросил меня подобрать ему на Wildberries зимние берцы без глухого или полуглухого клапана. На WB никто такой информации не предоставлял, ничего похожего в описаниях. И мне пришлось брать конкретные модели, находить их на сайте производителя, и только после этого вносить конкретную модель в список претендентов на покупку. (Да, купил я всё равно на WB – потому что не всё определяется контентом).
Выявив некоторую поисковую сущность с понятным семантическим окружением, поисковая система выявляет и связанные с ней страницы из своего индекса, и эти страницы могут в качестве атрибутов иметь совершенно неожиданные ключевые слова. Поисковая система в этом случае переформулирует запрос, выбирая наиболее понятный ей. Это можно считать своего рода «переколдовкой», но на более сложном уровне: поисковик переписывает запрос, сводя его к отличающемуся каноническому.
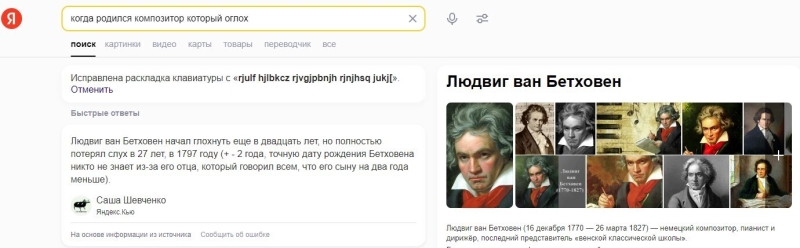
Запрос набран в неправильной раскладке, переколдован в правильную, заменен на вопрос о Бетховене. Яндекс знает, что композитор, который оглох – это чаще всего Бетховен.
Это очень простой пример контекстного поиска с явными результатами, но аналогичные алгоритмы работают и в других тематиках.
Главный вывод, который можно сделать из этого: вы едва ли можете повлиять на атрибуты и связи какой-то поисковой сущности, связанной с запросом. Вы можете их предсказать и частично выявить. Всё, с чем мы можем работать — это факторы улучшения контекста, независимые от запроса. Их и рассмотрим ниже.
На что можно повлиять, а на что – нет
Поисковая система должна понимать контекст. Для этого она использует разные данные, как на стороне пользователя, обращающегося к поиску, так и на стороне сайтов, условно соответствующих этому запросу.
На что может повлиять только формулировка запроса пользователем:
- В запрос добавлено время. Поисковая система покажет наиболее свежие результаты и новости.
- Запрос сформулирован как вопрос. Поисковая система постарается ответить на этот вопрос в нулевом блоке, в выделенных фрагментах.
- Запрос включает сущность. Вероятнее всего, поисковая система покажет официальный сайт, статью в «Википедии», либо другие подобные ресурсы.
- Общие неопределенные запросы. В этом случае поисковая система формирует выдачу, состоящую из разноплановых сайтов, отвечающих самым разным интентам пользователя.
К независимым от запроса факторам относят внешние факторы, связанные с пользователем:
- его устройство
- демографические данные
- местоположение
- время суток
- история поиска
и т.п.
Отталкиваясь от этих данных, поисковая система уже может формировать максимально релевантную (с её точки зрения) персонализированную выдачу. Вы не можете запросто поправить информацию в графе знаний, увеличить поисковый спрос и повлиять на результаты машинного обучения, но можете повлиять на отдельные элементы контекста.
Важно понимать, что речь идёт о машинном обучении, а контекст — это множество слоёв и схожих запросов, подразумевающих разные цели поиска (интенты).
Контекстные элементы
С некоторых пор в рунете прижилась аббревиатура КНДР («Контент, необходимый для ранжирования»). Речь идёт о некоторых контентных блоках, прямо влияющих на релевантность страницы запросу. Пример: если вы хотите, чтобы страница соответствовала запросу «ремонт квартиры цена» – вы должны показать прайс-лист. А вот «сколько стоит отремонтировать квартиру в Москве» – это чаще про сравнение ценников у разных исполнителей, и обычным прайс-листом там не обойтись. И совсем плохо, если у вас на страничке только кнопка «Запросить цену».
«Необходимый» здесь – вовсе не реально необходимый. Ранжироваться высоко можно и без него, речь только о предпочтительном для аудитории формате, который ожидает увидеть и поисковая система.
Контентные элементы могут представлять собой таблицы, картинки, видео, блоки вопросов/ответов. Поисковая система будет оценивать по ним назначение страницы, а качество – по пользовательским сигналам.
Не стоит думать, что есть какие-то канонические типы документов и структур страниц, соответствующих заданному кластеру запросов. Поисковая выдача – всегда тест: алгоритм выводит статью, видео, обзор, коммерческую страничку, чтобы понять, как будет реагировать аудитория. Соответственно, есть смысл тестировать и вам – или сочетать разные типы контента в рамках одного документа. И конечно же, обычную логику никто не отменял.
Однако пользовательские сигналы — это работа на перспективу. До того, как они в принципе начнут проявляться и на что-то влиять, надо обеспечить достаточный контекст для машины, поискового алгоритма. Возможно, это самая простая часть оптимизации, поскольку подразумевает простые и привычные средства.
Усиление контекстных сигналов для поисковых систем
Основные средства, с помощью которых можно проработать контекст.
- Связанные объекты (сущности) в основном контенте. Используйте любые доступные средства: анализ Графа Знаний Google, n-граммный анализ инструментами типа SEOlemma или даже «Акварель-Генератор», парсинг с последующим анализом инструментами Python. Важно выявить не просто связанные ключевые слова, а именно объекты.
- Текст ссылок – внешних и внутренних. Это один из старейших и очень эффективных инструментов проработки контекста. Если сомневаетесь – загляните в раздел «Быстрые ссылки» в Яндекс-Вебмастере и посмотрите на предлагаемые варианты этих быстрых ссылок.
- Выстраивание иерархии запросов и ответов в рамках страницы. Здесь работает принцип перевернутой пирамиды: начинаете с главного – дополняете второстепенным.
- Исключение несоответствующих запросов и слов, способных сместить акценты и негативно повлиять на определение тематики. Сюда же можно отнести и традиционную «воду». Известно, что Google присваивает контенту определенную «оценку тарабарщины», чтобы выявить бессмысленный контент, густо нашпигованный ключами. Кроме того, контент может быть определен как принадлежащий к тематике, к которой предъявляются более жёсткие требования, которым сайт реально не соответствует.
- Семантическое структурирование страницы – от уровня HTML до распределения каждого объекта в собственном блоке контента.
- Машиночитаемость – синтаксическая и семантическая. Поисковая система не понимает ваш текст. Всё, что она умеет – скачивать содержимое, выявлять ключевые слова и связи между ними, сопоставлять полученное с имеющимся в базе, оценивать пользовательский отклик. Если вы можете упростить эти процессы для машины – это может пойти на пользу ранжированию вашего сайта.
Как определить интенты без погружения в тематику
Хороший SEO-специалист должен изучить бизнес клиента. Но это требует времени, а в некоторых тематиках задача решается очень трудно. Да, вы можете опросить отдел продаж и напрямую выяснить, что чаще всего интересует потенциальных клиентов и добавить соответствующий контент на посадочные страницы. Но эта информация доступна не всегда. В этом случае на помощь приходит работа с данными.
Работу с данными можно также разделить на два основных варианта:
а) Извлечь данные непосредственно из сервисов поисковых систем. Например, воспользоваться CloudEnterpriseKnowledgeGraph: с его помощью можно:
- Получить список наиболее заметных объектов, связанных с заданным запросом
- Выявить список дополняющих элементов в запросах (то, что в рунете называется “Подсказочник”)
- Проработать структуры контента на объектах Knowledge Graph
- Определить пробелы в существующем контенте или структуре сайта
Дальше – вопрос задач и аналитики. Главное преимущество этого метода – вы получаете данные непосредственно из базы данных поисковой системы. Минусы:
-
Вы должны уметь работать с данными
-
В графе знаний хватает пробелов. Есть темы, где вы получите чуть больше, чем ничего: система опирается на доступные данные из интернета. А есть и очень противоречивые данные, опираться на которые нельзя.
б) Второй вариант – более доступный, хотя и опирается более на статистические данные из сторонних поисковых сервисов. Я использую keys.so, общую схему рассмотрим ниже.
Почему не «Вордстат»? – Вам нужна статистика видимости по запросам отдельных страниц, высоко ранжирующихся по заданному запросу. Это запросы связанные с основным, но не всегда включающих те же ключи.
- Возьмите самый частотный запрос продвигаемого кластера. Выгрузите статистику по нему вместе со списком сайтов, имеющих наилучшую видимость по запросу.
- Из полученного списка уберите сайты, ранжирующиеся не по причине реально высокого качества (сервисы Яндекса, «Дзен», маркетплейсы). И теперь последовательно выгружайте видимость страниц-конкурентов в топе по запросам в поиске. В зависимости от тематики – 3-10 сайтов будет достаточно.
- Выгруженные запросы соберите в единую табличку в Excel. Сгруппируйте эти запросы по входящих в них ключам и общим пользовательским намерениям. Вы получите группы типа «Цены», «Гарантийные условия», среди которых можно выявить ещё подгруппы. Пример: я выгрузил запросы кластера «адвокат по ДТП». После разделения запросов кластера на подгруппы («Представительство в суде», «Страховка», «Консультации» и т.д.) определились подгруппы типа «бесплатно», «без предоплаты». Если такие клиенты интересны заказчику – контент под них тоже придётся добавлять.
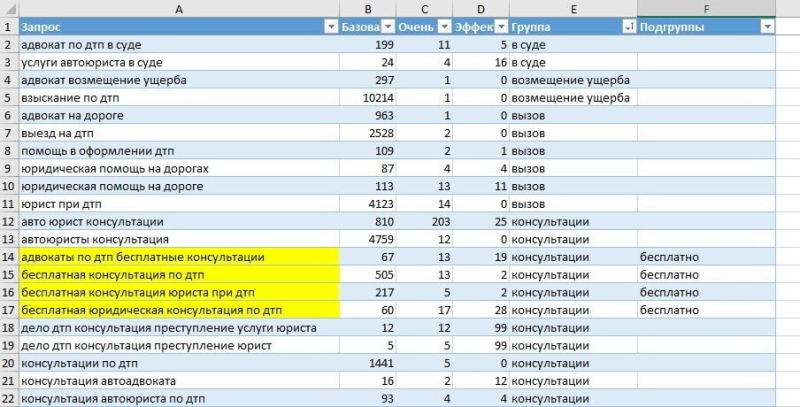
Пример группировки суб-кластеров. Жёлтым я выделил запросы, которые вот совсем неинтересны.
- Теперь можно сопоставить продвигаемую страницу с полученным списком целей, ради которых потенциальные клиенты зашли на сайт. Нет контента – добавляйте.
Особое внимание стоит уделить тем запросам, которые устойчиво повторяются на всех добавленных в список сайтах. Частотность у них может быть совсем малой, и это не повод их игнорировать. Такие микрочастотные запросы могут определять общую релевантность страницы более частотным ключевым словам.
Сайты, имеющие минимум запросов по кластеру, стоит выбрасывать: вероятно, речь идёт о низкой релевантности страницы запросу. Тот же WB может соответствовать 1-2 ключевым словам при том, что реально релевантные страницы видны по десяткам и сотням ключевиков.
Вернитесь к поисковой выдаче и оцените блок “Люди также спрашивают”. Этот раздел автоматически создаётся на базе данных по истории поиска. Здесь выводятся запросы, которые пользователи отправляют в поиск, чтобы завершить поиск.
Оцените типы контента, который поисковые системы и пользователи считают предпочтительным. Сопоставьте каждый тип с соответствующими ему суб-интентами. Для этого вам придётся глазами посмотреть на контент страниц в топе: в некоторых случаях релевантность определяется встроенным видео, табличкой или картинкой с инфографикой. Об этом – ниже.
Проработка контекста – это диалог
Итак, вы грубо выявили суб-интенты, каждый из которых должен иметь свой контентный блок. Время разобраться, что должно присутствовать в этих блоках.
Главный принцип контекстной оптимизации – это буквальное выстраивание диалога с посетителем. Вы должны выстроить целостную последовательность запросов и ответов, начиная с базового запроса и вплоть до связанных, неочевидных, но логически укладывающихся в конверсионную цепочку (какова бы ни была цель этой цепочки). Поисковые системы прекрасно знают, что и для чего, и в какой последовательности спрашивает представитель той или иной аудитории и что показать ему на определенные запросы.
Пример. У вас посадочная страница на сайте адвоката, оптимизируемая под кластер «адвокат дтп». Потенциальный клиент сбил кого-то на дороге и ему срочно нужна защита. Вот он стоит на шоссе ночью, лихорадочно листая телефон в состоянии жёсткого стресса. Какие вопросы его могут интересовать в этот момент?
- Когда адвокат сможет приехать на место происшествия?
- Что сделать, чтобы мне ответили как можно быстрее?
- Что можно, необходимо и что нельзя делать до приезда адвоката?
- Может ли адвокат выступать в качестве свидетеля?
- Есть ли смысл пытаться откупиться прямо на месте или этого делать нельзя?
А теперь представьте, что вместо заметных и доступных подсказок на страничке – сложные юридические формулировки, отсутствие прямых указаний, что делать и предложение оставить телефон для бесплатной консультации. Всё это, разумеется, также необходимо – но не сейчас и не для этой аудитории.
Первое, что будет искать человек в такой ситуации – это контакты, регион, в котором адвокат работает, ссылку на страницу, описывающую его ситуацию – и внятную простую инструкцию. А теперь посмотрите на сайты московских адвокатов, занимающих топ Яндекса. Что из этого вы найдёте? – В лучшем случае – контакты. Всё остальное – мокрая вода, список регалий, «как мы работаем», какие-то видео с отзывами. Негусто. Сравните с аналогичными сайтами в Нью-Йорке. Почувствуйте разницу.
Помощь в определении обязательных данных окажет всё тот же блок «Люди ищут». Как уже было сказано, этот блок состоит из запросов, дополняющих поиск по заданным ключевым словам. Используйте эти данные.
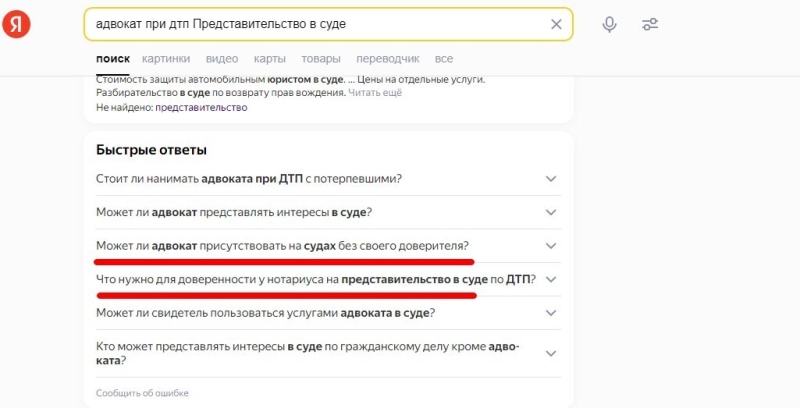
Некоторые идеи по доработкам контента на базе быстрых ответов из поиска
Заключение
- Нет совершенных страниц, способных закрыть любой пользовательский интент. Любая страница, даже находящаяся в топ-1, будет иметь пробелы контекстного характера, и фактически нет точного способа это диагностировать. Однако заполнение контекстных пробелов способно обеспечить большую релевантность запросам, а вместе с этим – и большую ценность сайта для поисковых систем.
- Важно обеспечить не максимально широкий спектр соответствия пользовательским намерениям, не максимальный объём трафика из поиска, а способность достижения целей этого поиска целевой аудиторией.
- Контекстные лакуны стоит понимать в более широком смысле: речь не только об отсутствии в текстовом контенте конкретной страницы ожидаемых поисковой системой и пользователями поисковых сущностей и объектов, но и о формате представленного контента, а также взаимосвязях между заданным контентом на странице с контентом других страниц.
- Современные поисковые системы – это не только браузер на ПК. Это смартфон, голосовые помощники, чат-боты.
Ранжирование на базе оценки ключевых слов всё ещё остаётся базой для поиска. Но эти алгоритмы ощутимо теряют вес и замещаются более сложными, оценивающими смысл запроса, его цели и эффективность применительно к целевой аудитории.
Monstro – сервис для продвижения сайтов и услуг
https://t.me/monstrotraf