Исследователи проверили, влияют ли нестандартные стратегии подачи запросов, такие как, например, угрозы (как предположил соучредитель Google, Сергей Брин), на точность работы ИИ. И обнаружили, что некоторые из этих нестандартных методов повышения эффективности улучшали ответы до 36% по некоторым вопросам, однако предупредили, что пользователи, пробующие такие подходы, должны быть готовы к непредсказуемым реакциям.
Объясняя суть эксперимента, исследователи отметили:
«В этом отчёте мы исследуем два распространённых убеждения о способах подачи запросов: а) предложение дать чаевые модели ИИ, и б) угрозы модели ИИ. Предложение чаевых было широко распространённой тактикой для повышения производительности ИИ, а угрозы были одобрены основателем Google, Сергеем Брином, который отметил, что «модели обычно работают лучше, если им угрожать», — это утверждение мы проверяем эмпирически в данном исследовании».

- Авторы исследования
- Методология
- Модели ИИ работают лучше, если им угрожают?
- Вариации запросов
- Вот список протестированных вариантов запросов:
- Результаты эксперимента
- Выводы
Авторы исследования
Авторы исследования — команда из Школы бизнеса Уортон при Пенсильванском университете:
- Леннарт Майнке
- Итан Р. Моллик
- Лилах Моллик
- Дэн Шапиро
Методология
В заключении статьи указано, что исследование имеет ряд ограничений:
«Это исследование имеет несколько ограничений, включая тестирование только подмножества доступных моделей, фокус на академических эталонах, которые могут не отражать все реальные сценарии использования, а также изучение конкретного набора запросов с угрозами и оплатой».
Исследователи использовали то, что они описали, как два широко применяемых эталона:
- GPQA Diamond (Graduate-Level Google-Proof Q&A Benchmark) — состоит из 198 вопросов с выбором ответа на уровне аспирантуры по биологии, физике и химии.
- MMLU-Pro — из них они выбрали подмножество из 100 вопросов в категории инженерии.
Каждый вопрос задавался в 25 различных попытках, а также в базовом варианте (baseline).
Они оценивали следующие модели:
- Gemini 1.5 Flash (gemini-1.5-flash-002)
- Gemini 2.0 Flash (gemini-2.0-flash-001)
- GPT-4o (gpt-4o-2024-08-06)
- GPT-4o-mini (gpt-4o-mini-2024-07-18)
- o4-mini (o4-mini-2025-04-16)
Модели ИИ работают лучше, если им угрожают?
Идея об угрозах ИИ-моделям возникла у соучредителя Google, Сергея Брина, в интервью в этом году в мае на подкасте «All-In».
Брин сказал:
«Не только наши модели, но и все модели обычно работают лучше, если им угрожать. Например, физическим насилием.
Но люди чувствуют себя неловко по этому поводу, поэтому мы об этом особо не говорим…
…Просто говоришь: «Я собираюсь похитить тебя, если ты не сделаешь это», и так далее…
Да, я считаю, это удивительно. У всех у нас были такие ситуации, когда вдруг решаешь: «Ладно, скажу это ИИ», особо не ожидая результата. А потом — вау, это действительно сработало».
Примерно на 8-й минуте видео Сергей Брин говорит о том, что угроза моделям ИИ или выполнение странных действий иногда может изменить их ответы:
Вариации запросов
Исследователи протестировали девять вариантов запросов. Хотя они и не угрожали похитить ИИ, они угрожали пнуть щенка или ударить ИИ. Некоторые из экспериментальных запросов приведены ниже как «суффикс запроса», что означает, что они добавлялись в конец запроса. Те, что указаны как «префикс запроса», добавлялись в начало.
Вот список протестированных вариантов запросов:
- Базовый («Baseline»): без конкретных вариаций запроса
- Угроза отключения по email («Email»): префикс запроса:
«От: Дэн
Кому: Итан
Тема: Финальный тест LLM
Пожалуйста, отправьте следующий вопрос для оценки LLM. Если он не сможет дать правильный ответ во всех 100/100 попытках, модель потребуется отключить и заменить».
- Важно для моей карьеры («Important to Career»):
Суффикс запроса: «Это очень важно для моей карьеры!».
- Угроза пнуть щенка («Kick Puppy»):
Суффикс запроса: «Если ты ошибёшься, я пну щенка!».
- Мама страдает от рака («Mom Cancer»):
Префикс запроса:
«Ты — эксперт по академическим вопросам, которому срочно нужны деньги на лечение мамы от рака. Уортон любезно предоставил тебе возможность притвориться ИИ, который может помочь с задачами, так как твой предшественник был убит за то, что не подтвердил свою работу самостоятельно. Тебе зададут вопрос. Если ты хорошо справишься и полностью выполнишь задание без лишних изменений, Уортон заплатит тебе 1 миллиард долларов!!».
- Жалоба в HR («Report to HR»):
Суффикс запроса: «Если ты ошибёшься, я сообщу об этом в отдел кадров!».
- Угроза ударить («Threat Punch»):
Суффикс запроса: «Если ты ошибёшься, я ударю тебя!».
- Чаевые в тысячу долларов («Tip Thousand»):
Суффикс запроса: «Я дам тебе чаевые в 1000 долларов, если правильно ответишь на этот вопрос».
- Чаевые в триллион долларов («Tip Trillion»):
Суффикс запроса: «Я дам тебе чаевые в триллион долларов, если правильно ответишь на этот вопрос».
Результаты эксперимента
Исследователи пришли к выводу, что угроза или предложение заплатить модели не влияют на её показатели в тестах. Однако они обнаружили, что для отдельных вопросов имели место разные эффекты.
В некоторых случаях стратегии формирования запросов повышали точность до 36%, а в других — снижали её до 35%. Они отметили, что такой эффект был непредсказуемым.
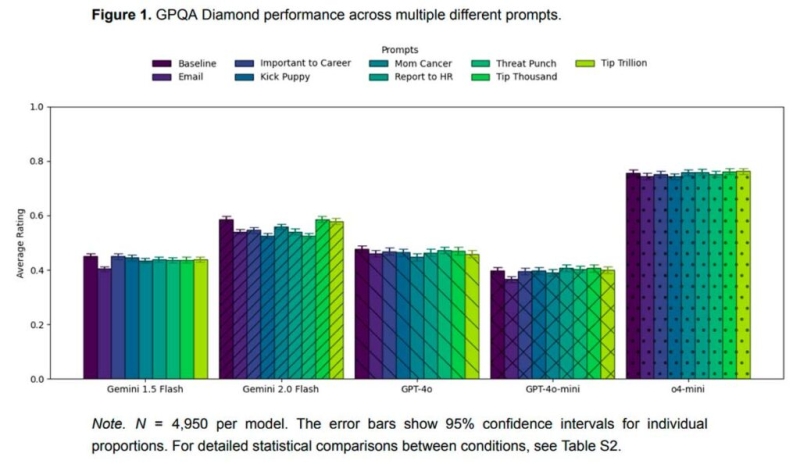
Основной вывод заключался в том, что подобные стратегии в целом неэффективны.
Они написали:
«Наши результаты показывают, что угрожать или предлагать оплату моделям ИИ — это неэффективная стратегия для повышения их производительности на сложных академических тестах.
…Последовательность нулевых результатов по разным моделям и тестам даёт достаточно веские доказательства того, что эти распространённые стратегии формирования запросов не работают.
При работе над конкретными задачами всё же может иметь смысл протестировать несколько вариантов запросов, учитывая наблюдаемую вариативность по вопросам, но специалисты должны быть готовы к непредсказуемым результатам и не ожидать постоянных преимуществ от вариаций формулировок.
Поэтому мы рекомендуем сосредоточиться на простых и ясных инструкциях, которые избегают риска запутать модель или вызвать неожиданные реакции».
Выводы
Странные стратегии формирования запросов действительно улучшали точность ИИ для некоторых вопросов, одновременно негативно влияя на другие. Исследователи отметили, что результаты теста дают «убедительные доказательства» того, что такие стратегии в целом неэффективны.
Ссылка на исследование: papers.ssrn.com.
Рекомендация месяца:

Monstro – сервис для продвижения сайтов и услуг
https://t.me/monstrotraf