
Явные и неявные дубли на сайте затрудняют индексацию, ломают планы по продвижению и могут «подарить» вебмастеру часы и часы работы по их удалению. Как избежать проблем и вовремя их ликвидировать? Рассказываем в статье.
Дубли — это страницы на одном и том же домене с идентичным или очень похожим содержимым. Чаще всего появляются из-за особенностей работы CMS, ошибок в директивах robots.txt или в настройке 301 редиректов.
Появления дублей можно избежать на начальном этапе технической оптимизации сайта, еще до того, как он начнет индексироваться. Для каждого типа описали свои способы профилактики. Если значительная часть страниц-дублей с вашего ресурса уже попала в индекс, распределите их по типам, проведите работу по устранению и поисковики сами постепенно удалят их из выдачи.
В чем опасность дублей
1. Неправильная идентификация релевантной страницы поисковым роботом. Допустим, у вас одна и та же страница доступна по двум URL:
https://site.ru/kepki/
https://site.ru/catalog/kepki/
Вы вкладывали деньги в продвижение страницы https://site.ru/kepki/. Теперь на нее ссылаются тематические ресурсы, и она заняла позиции в топ-10. Но в какой-то момент робот исключает ее из индекса и взамен добавляет https://site.ru/catalog/kepki/. Естественно, эта страница ранжируется хуже и привлекает меньше трафика.
2. Увеличение времени, необходимого на переобход сайта роботами. На сканирование каждого ресурса у поисковых роботов есть краулинговый бюджет — максимальное число страниц, которое робот может посетить за определенный отрезок времени. Если на сайте много дублей, робот может так и не добраться до основного контента, из-за чего его индексация затянется. Эта проблема особенно актуальна для сайтов с тысячами страниц.
3. Наложение санкций поисковых систем. Сами по себе дубли не являются поводом к пессимизации сайта — до тех пор, пока поисковые алгоритмы не посчитают, что вы создаете дубли намеренно с целью манипуляции выдачей.
4. Проблемы для вебмастера. Если работу над устранением дублей откладывать в долгий ящик, их может накопиться такое количество, что вебмастеру чисто физически будет сложно обработать отчеты, систематизировать причины дублей и внести корректировки. Большой объем работы повышает риск ошибок.
Дубли условно делятся на две группы: явные и неявные.
Явные дубли (страница доступна по двум или более URL)
Вариантов таких дублей много, но все они похожи по своей сути. Вот самые распространенные.
1. URL со слешем в конце и без него
Пример:
https://site.ru/list/
https://site.ru/list
Что делать: настроить ответ сервера «HTTP 301 Moved Permanently» (301-й редирект).
Как это сделать:
- найти в корневой папке сайта файл .htaccess и открыть (если его нет — создать в формате TXT, назвать .htaccess и поместить в корень сайта);
- прописать в файле команды для редиректа с URL со слешем на URL без слеша:
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} ^(.+)/$
RewriteRule ^(.+)/$ /$1 [R=301,L]
- обратная операция:
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_URI} !(.*)/$
RewriteRule ^(.*[^/])$ $1/ [L,R=301]
- если файл создается с нуля, все редиректы необходимо прописывать внутри таких строк:
<IfModule mod_rewrite.c>
…
</IfModule>
Настройка 301 редиректа с помощью .htaccess подходит только для сайтов на Apache. Для nginx и других серверов редирект настраивается другими способами.
О других полезных возможностях файла .htaccess читайте в блоге PromoPult.
Какой URL предпочтителен — со слешем или без? Чисто технически — никакой разницы. Смотрите по ситуации: если проиндексировано больше страниц со слешем, оставляйте этот вариант, и наоборот.
2. URL с WWW и без WWW
Пример:
https://www.site.ru/1
https://site.ru/1
Что делать: указать на главное зеркало сайта в Яндекс Вебмастере, настроить 301 редирект и канонические URL.
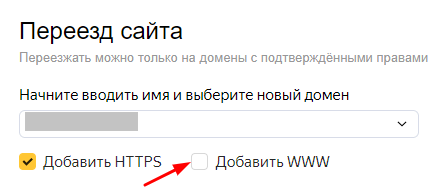
Как указать главное зеркало в Яндексе
- перейти в Яндекс Вебмастер и добавить 2 версии сайта — с WWW и без WWW;
- выбрать сайт, с которого будет идти перенаправление (чаще всего перенаправляют на URL без WWW);
- перейти в раздел «Индексирование / Переезд сайта», убрать галочку напротив пункта «Добавить WWW» и сохранить изменения.
В течение 1,5 – 2 недель Яндекс склеит зеркала, переиндексирует страницы, и в поиске появятся только URL без WWW.
Важно! Ранее для указания на главное зеркало в файле robots.txt необходимо было прописывать директиву Host. Но она больше не поддерживается. Некоторые вебмастера «для подстраховки» до сих пор указывают эту директиву — в этом нет необходимости, достаточно настроить склейку в Вебмастере.
Как склеить зеркала в Google
Указать поисковику на главное зеркало можно двумя способами:
- Настроить 301 редирект на предпочтительную версию. Если вы не сделали это сразу же после того, как открыли сайт для индексации, проанализируйте, каких страниц больше в индексе Google и настраивайте переадресацию на этот вариант URL.
- Согласно рекомендациям Google, настроить канонические страницы: добавить в код тег <link> с атрибутом rel="canonical" или включить в ответ страниц HTTP-заголовок rel=canonical.
Анализ индексации страниц в PromoPult поможет локализовать большинство проблем с индексацией. Проверяет обе поисковые системы. Быстро покажет косяки индексации. Гайд по работе с инструментом — здесь.
3. Адреса с HTTP и HTTPS
Сайты с SSL-сертификатами получают преимущество в результатах выдачи. Но из-за ошибок при переходе на HTTPS появляются дубли:
https://www.site.ru
http://site.ru
Что делать:
1. Проверить, корректно ли склеены зеркала в Яндексе (процедура аналогична склейке зеркал с WWW и без WWW, с той лишь разницей, что в главном зеркале нужно установить галочку «Добавить HTTPS»).
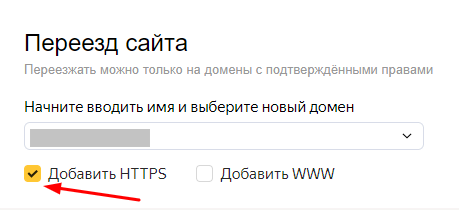
2. Проверить, правильно ли настроены редиректы. Возможно, в использованном коде есть ошибки. У нас есть пошаговая инструкция по настройке HTTPS, где даны все необходимые команды для редиректов.
Важно! Если с момента настройки HTTPS прошло менее 2 недель, не стоит бить тревогу — подождите еще неделю-другую. Поисковикам нужно время, чтобы убрать из индекса старые адреса.
4. Адреса с GET-параметрами
Все, что идет в URL после знака ?, называется GET-параметрами. Эти параметры разделяются между собой знаком &. Каждый новый URL с GET-параметрами является дублем исходной страницы.
Примеры:
Исходная страница: http://site.ru/cat1/gopro
URL с UTM-метками: http://site.ru/cat1/gopro?utm_source=google&utm_medium=cpc&utm_campaign=poisk
URL с идентификатором сессии: http://site.ru/cat1/gopro?sid=x12k17p83
URL с тегом Google Ads: http://site.ru/cat1/gopro?gclid=Kamp1
Что делать:
Вариант 1. Запретить индексацию страниц с GET-параметрами в robots.txt. Выглядеть запрет будет так (для всех роботов):
User-agent: *
Disallow: /*?utm_source=
Disallow: /*&utm_medium=
Disallow: /*&utm_campaign=
Disallow: /*?sid=
Disallow: /*?gclid=
Вариант 2. Яндекс поддерживает специальную директиву Clean-param для robots.txt, которая дает команду роботу не индексировать страницы с GET-параметрами. Ее преимущество в том, что если исходная страница по какой-то причине не проиндексирована, то робот по директиве Clean-param узнает о ее существовании и добавит в индекс. Если же закрыть от индексации страницы с GET-параметрами с помощью директивы Disallow, то робот даже не будет обращаться к этим страницам, и исходная страница так и останется не проиндексированной.
Подробная информация об использовании директивы – в Справке Яндекса.
Проблема в том, что директива Clean-param применяется в Яндексе, и Google не понимает ее. Поэтому решение такое: для Яндекса используем Clean-param, для Google — Disallow:
User-agent: Yandex
Clean-param: utm_source&utm_medium&utm_campaign&sid&gclid
User-agent: Googlebot
Disallow: /*?utm_source=
Disallow: /*&utm_medium=
Disallow: /*&utm_campaign=
Disallow: /*?sid=
Disallow: /*?gclid=
Читайте также:
SEO термины: краткий экскурс в мир поисковой оптимизации для новичков
5. Один и тот же товар, доступный по разным адресам
Пример:
http://site.ru/catalog/sony-ps-4
http://site.ru/sony-ps-4
Что делать: настроить атрибут rel="canonical" для тега <link>. Этот атрибут указывает на надежную (каноническую) страницу. Именно такая страница попадет в индекс.
Допустим, вам нужно указать роботу, чтобы он индексировал страницу http://site.ru/catalog/sony-ps-5. То есть именно она является канонической, а страница http://site.ru/sony-ps-5 — копией. В этом случае необходимо в раздел страницы-копии (и всех прочих страниц-копий, если они есть), добавить такую строку:
<link rel="canonical" href=»http://site.ru/catalog/sony-ps-5" />
Так вы со страницы-копии ссылаетесь на каноническую страницу, которая и будет индексироваться.
Настраивается rel="canonical" средствами PHP, с помощью встроенных функций CMS или плагинов. Например, для WordPress есть плагин All in One SEO Pack, который позволяет управлять каноническими URL в автоматическом и ручном режиме.
6. Версии для печати
Основной текстовый контент исходной страницы и версии для печати совпадает, поэтому такие страницы считаются дублями.
Пример:
Исходная страница: http://site.ru/article1.html
Версия для печати: http://site.ru/article1.html/?print=1
Или такой вариант реализации: http://site.ru/article1.html/print.php?postid=12
Что делать: закрыть доступ робота к версиям для печати в robots.txt. Если страницы на печать выводятся через GET-параметр ?print, используем для Яндекса директиву Clean-param, а для Google — Disallow:
User-agent: Yandex
Clean-param: print
User-agent: Googlebot
Disallow: /*?print=
Во втором примере реализации вывода на печать достаточно просто указать директиву Disallow для обоих роботов:
User-agent: *
Disallow: /*print.php
Ищите свой вариант работы с дублями
Одни и те же дубли можно закрыть от индексации разными способами. На практике работает и канонизация страниц, и редиректы, и директивы robots.txt, и метатег robots. Но каждый поисковик дает свои рекомендации.
Google не приветствует закрытие доступа к дублям с помощью robots.txt или метатега robots со значениями "noindex,nofollow", а предлагает использовать rel="canonical" и 301 редирект. А вот Яндексу robots.txt «по душе» — здесь даже есть своя директива Clean-param, о которой мы рассказывали выше.
Ваша задача — найти способы, которые будут оптимальны именно в вашем случае. Например, если вы ориентируетесь на аудиторию стран Запада или СНГ, лучше за основу брать рекомендации Google. Для России лучше придерживаться рекомендаций Яндекса.
Закрывать дубли сразу всем арсеналом инструментов точно не стоит — это лишняя работа, которая к тому же может привести к путанице в дальнейшем. Также не стоит излишне перегружать сервер 301 редиректами, поскольку это увеличит нагрузку на него.
Читайте также:
Как в один клик собрать метатеги и заголовки с любого сайта
Неявные дубли (контент на нескольких страницах различается, но незначительно)
Итак, мы разобрались с явными дублями — теперь расскажем о неявных, то есть тех, которые по разным URL отдают не идентичный, но очень похожий контент.
1. Дубли древовидных комментариев (replytocom)
Проблема актуальна для сайтов на WordPress. Когда кто-то отвечает на комментарий к записи, CMS генерирует новый URL. И чем больше ответов, тем больше дублирующихся URL, которые благополучно индексируются.
Что делать:
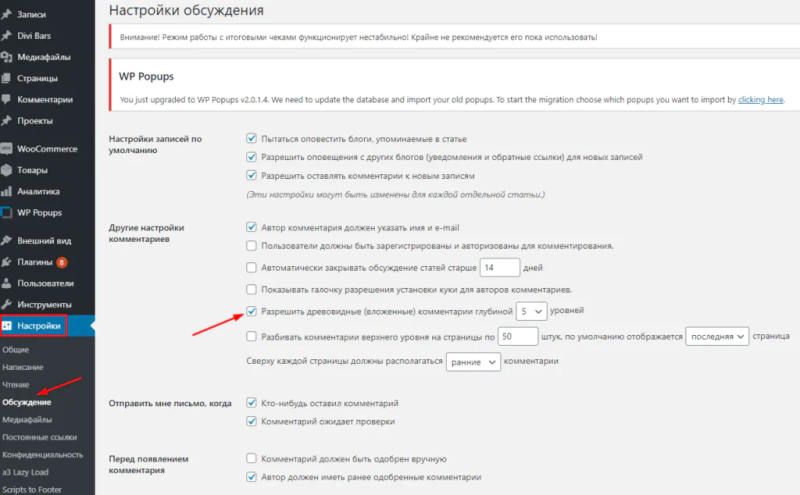
Вариант 1. Отключить древовидные комментарии в (перейти в «Настройки» / «Обсуждение», убрать галочку напротив «Разрешить древовидные (вложенные) комментарии глубиной N уровней» и не забыть сохранить изменения).
Но в этом случае снижается удобство комментирования. Поэтому лучше воспользоваться другими способами.
Вариант 2. Отключить штатный модуль комментариев и установить систему Disqus или аналоги (wpDiscuz, Cackle Comments и др.). Это и проблему с дублями устранит, и пользователям будет удобней.
Вариант 3. Изменить в коде CMS способ формирования URL страниц с ответами на комментарии и закрыть URL с replytocom от индексации с помощью метатега robots со значениями "noindex,nofollow". Для этой работы необходимо привлечь программиста.
2. Страницы товаров со схожими описаниями
Часто в интернет-магазинах товары отличаются лишь одной-двумя характеристиками (цвет, размер, узор, материал и т. п.). В итоге масса карточек товаров имеют однотипный контент. Это приводит к тому, что поисковик индексирует одну карточку (которую он считает наиболее подходящей), а похожие — нет.
Что делать:
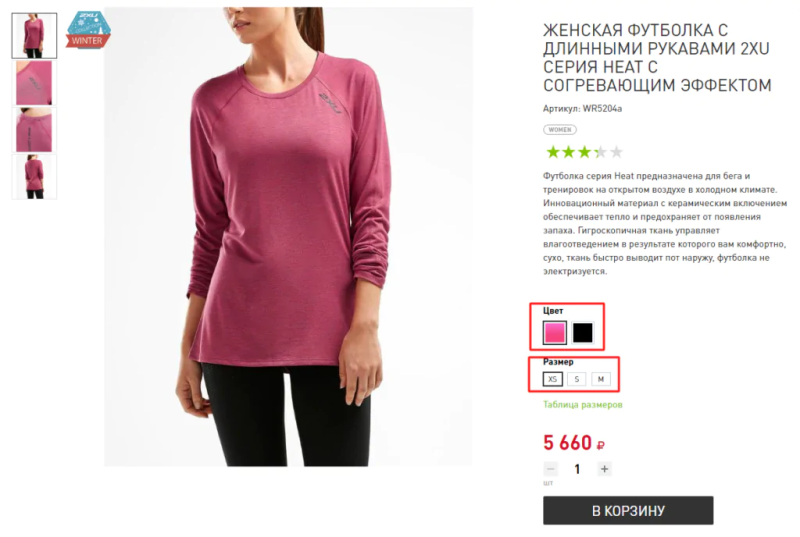
Вариант 1. Объединить однотипные товары в одной карточке и добавить селектор для выбора отличающихся параметров. Это избавляет от дублей и упрощает навигацию для пользователей.
Вариант 2. Если не получается добавить селекторы, уникализируйте описания однотипных товаров. Начните с наиболее значимых товаров, которые обеспечивают наибольшую прибыль. Так вы постепенно заполните карточки товаров уникальными описаниями, и они не будут восприниматься как дубли.
Вариант 3. Если в карточках товаров повторяется определенная часть описания, и ее нет смысла уникализировать (например, базовые заводские параметры), эту часть можно скрыть от индексации с помощью тега:
<!–noindex–>здесь повторяющийся текст<!–/noindex–>
Те же параметры, которые у товаров различаются, закрывать не стоит. Так поисковые системы будут видеть, что это разные товары.
Этот способ подходит скорее как временное решение. Особенно с учетом того, что тег noindex воспринимает только Яндекс. Лучше использовать первый или второй способ.
3. Страницы пагинации
Если у вас обширный каталог, то для удобства пользователей он разбивается на страницы. Это и есть пагинация.
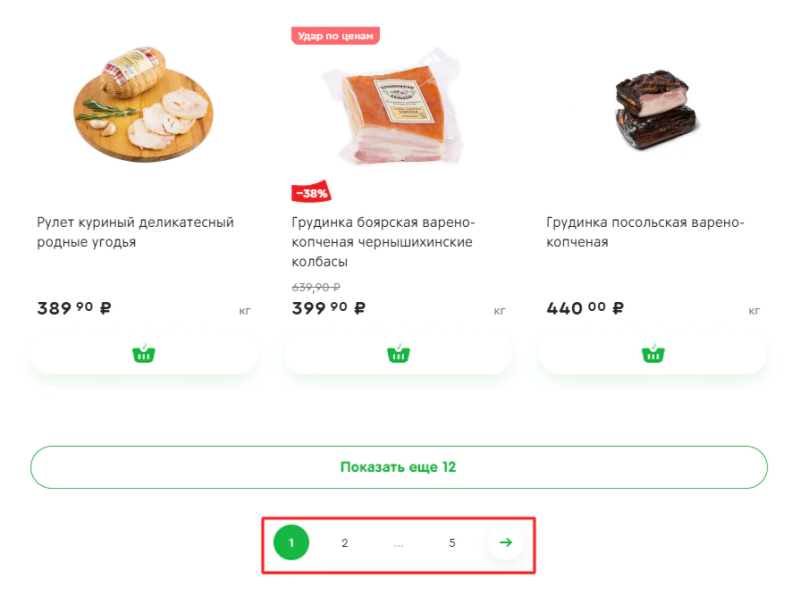
Для скрытия страниц пагинации от индексации эффективней всего использовать атрибут rel="canonical" тега </code>. В качестве канонической необходимо указывать основную страницу каталога.
Дополнительно обезопасить сайт от появления дублей страниц пагинации в индексе можно при помощи генерации уникальных метатегов title и description и заголовков h1 по следующему шаблону:
- [Title основной страницы пагинации] – номер страницы пагинации;
- [Description основной страницы пагинации] – номер страницы пагинации;

Пример генерации title и description для страниц пагинации
- h1 основной страницы пагинации – номер страницы пагинации.
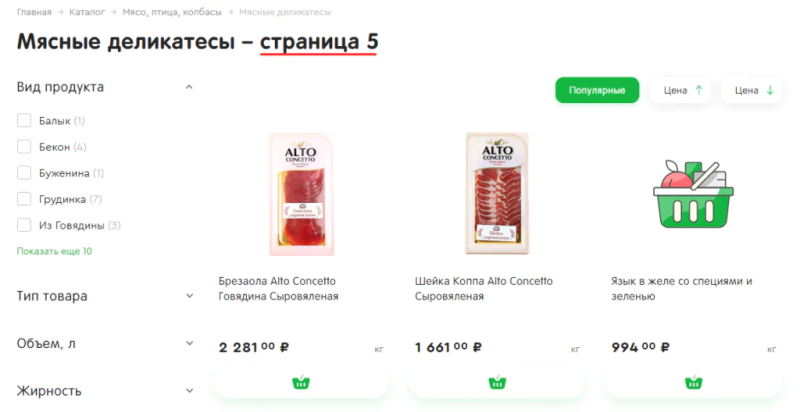
Пример генерации h1 для страниц пагинации
При оптимизации страниц пагинации также нужно учесть два важных момента:
- Не стоит добавлять на страницы пагинации уникальные тексты. Это лишняя трата времени и денег — контент на этих страницах и так различается (разные товары). Дело не в уникальном контенте, а в том, что пользователю нет смысла попадать из поиска на 3-ю или 10-ю страницу каталога. Ему важно начать с начала, а потом он уже сам решит, двигаться дальше или нет.
- Если в интернет-магазине размещены SEO-тексты на категориях товаров, они должны отображаться только на первой странице, чтобы избежать дублирования контента.
Мы рассмотрели основные дубли. Но вариантов может быть множество. Главное — понимать, как они формируются, как с ними бороться и с помощью каких инструментов выявить.
Читайте также:
Как бесплатно проверить позиции сайта в поисковых системах
Как выявить дубли страниц
Сложного в этом ничего нет. Покажем несколько способов — выбирайте любой.
Способ 1. «Ручной»
Зная особенности своей CMS, можно быстро вручную найти дубли в поисковиках. Для этого введите в поисковой строке такой запрос:
site:{ваш домен} inurl:{фрагмент URL}
Например, мы знаем, что на сайте URL страниц пагинации формируются с помощью GET-запроса ?page=. Вводим в Яндекс запрос и находим дубли:
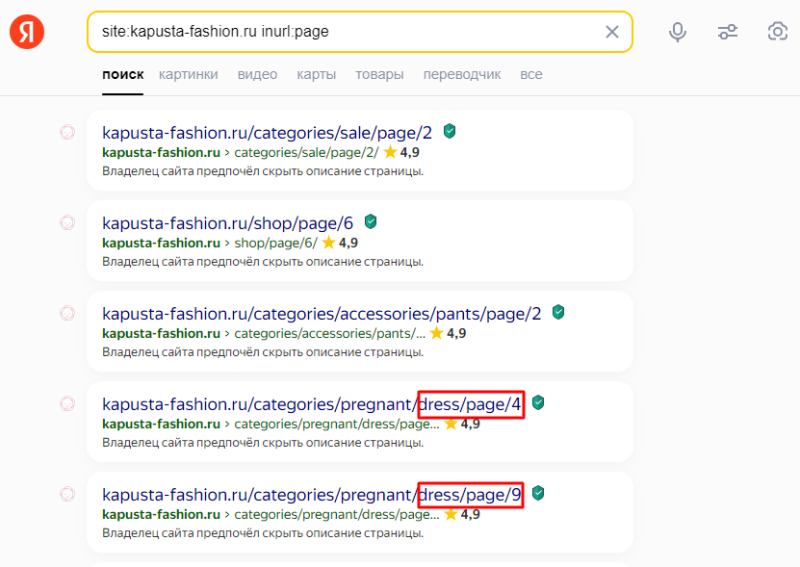
То же самое делаем в Googlе.
Если выяснится, что в дублирующихся страницах встречаются запросы ?limit=, ?start=, ?category_id= — по ним тоже стоит проверить сайт на наличие дублей.
Этот способ хорошо подходит для экспресс-анализа сайта. Для системной работы используйте другие способы.
Способ 2. Яндекс Вебмастер
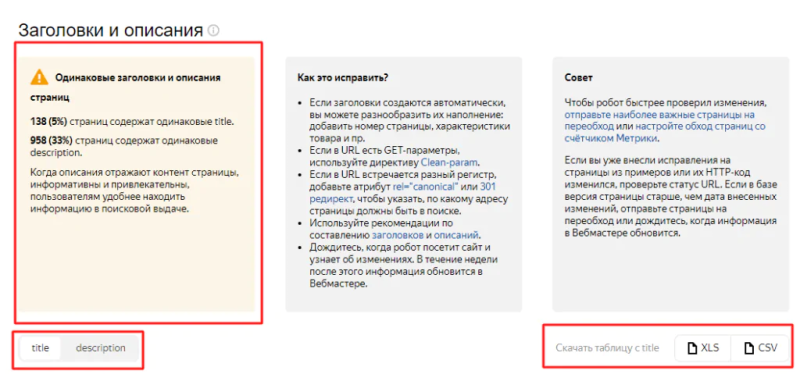
Сообщения о дублях страниц, которые обнаружил на сайте робот Яндекса, появляется в разделе «Диагностика». Например, так выглядит уведомление о страницах с одинаковыми title и description:
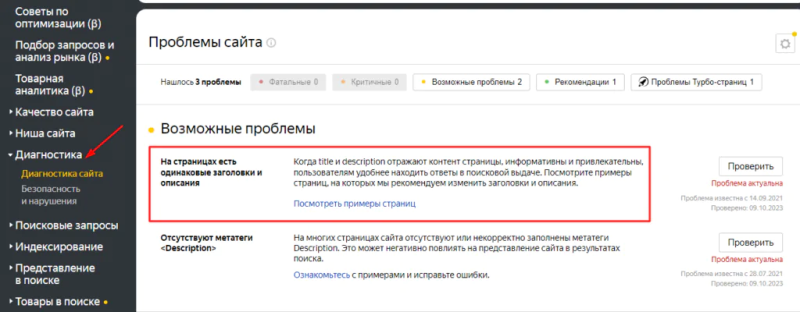
Также Яндекс предупредит о наличии на сайте страниц с незначащими GET-параметрами.
Примеры страниц с одинаковыми тегами title и description собраны в разделе «Индексирование» / «Заголовки и описания».
При наличии дублей метатегов, здесь будет информация о количестве затронутых страниц (это же уведомление будет в разделе «Сводка»), примеры и рекомендации по исправлению. Таблицу с URL можно выгрузить в форматах XLS и CSV.
Разумно не ждать уведомлений и самостоятельно выявить дубли страниц с помощью Вебмастера. Алгоритм несложный:
- Перейдите в раздел «Индексирование» / «Страницы в поиске».
- Активируйте вкладку «Все страницы» и выгрузите отчет в формате XLS:
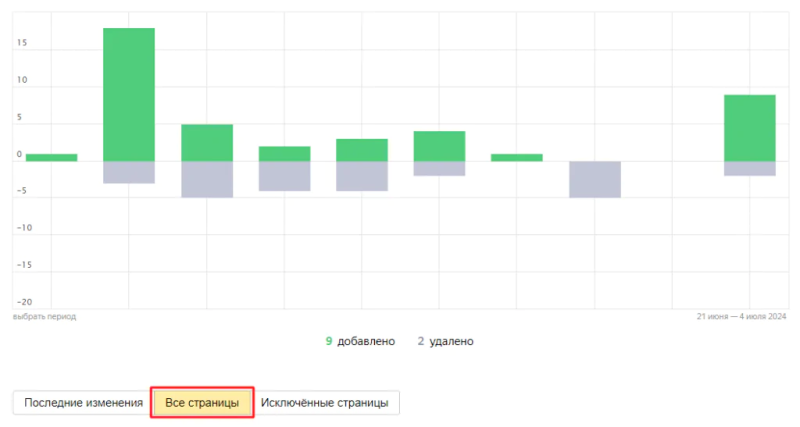
- Пройдитесь по списку и найдите «подозрительные» URL. Для удобства активируйте фильтры по частям URL, указывающим на дублирование.
Способ 3. Парсинг проиндексированных страниц
При отслеживании индексации в панели Яндекса проблематично сопоставить данные с Google — приходится вручную перепроверять, проиндексирован ли здесь дубль. Избежать такой проблемы позволяет парсер проиндексированных страниц от PromoPult.
Что нужно сделать:
- выгрузите список проиндексированных URL из Яндекс Вебмастера;
- загрузите этот список в инструмент от PromoPult — списком или с помощью XLSX-файла (подробная инструкция по использованию инструмента);
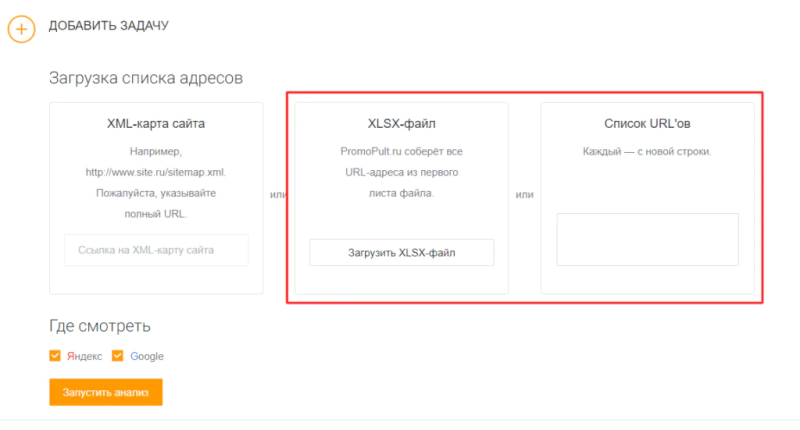
- запустите анализ и скачайте результат.

В этом примере страницы пагинации проиндексированы и Яндексом, и Google. Решение — настроить канонизацию для страниц пагинации и по возможности уникализировать метаданные.
Используя парсер от PromoPult, вы поймете, дублируются страницы в обоих поисковиках или только в одном. Это позволит подобрать оптимальные инструменты решения проблемы.
Если нет времени или опыта разбираться с дублями
Если у вас нет времени на то, чтобы разобраться с дублями, закажите аудит сайта — помимо наличия дублей вы получите массу полезной информации о своем ресурсе: наличие ошибок в HTML-коде, заголовках, метатегах, структуре, внутренней перелинковке, юзабилити, оптимизации контента и т. д. В итоге у вас на руках будут готовые рекомендации, выполнив которые, вы сделаете сайт более привлекательным для посетителей и повысите его позиции в поиске.
Еще один вариант — запустить поисковое продвижение сайта в SEO-модуле PromoPult. Специалисты выполнят более 70 видов работ по оптимизации сайта по чек-листу (в том числе устранят дубли). В итоге вы получите привлекательный для пользователей сайт, который будет стабильно расти в поиске и получать органический трафик.
Реклама. ООО «Клик.ру», ИНН 7743771327, ERID: 2Vtzqx6mCGs
Monstro – сервис для продвижения сайтов и услуг
https://t.me/monstrotraf