Любой сайт в интернете не может работать без веб-сервера. Веб-сервер принимает запросы от пользователей, обращается к файлам сайта и отдает контент пользователю: HTML, JSON, картинки, файлы или потоковые данные.
Все популярные веб-серверы, которые обычно используются при создание сайтов, например Nginx или Apache — имеют поддержку логов. Логи — это текстовые файлы, что-то вроде журналов, куда записывается информация о всех совершенных запросах на сервер. А также об ошибках.
Для нас важны логи запросов. О них мы сегодня и поговорим. Но для начала небольшой экскурс в технические аспекты вопроса.
Как работает веб-сервер?
Если говорить совсем просто, то веб-сервер — это посредник между браузером и содержимым сайта: HTML файлами, скриптами и другим контентом.
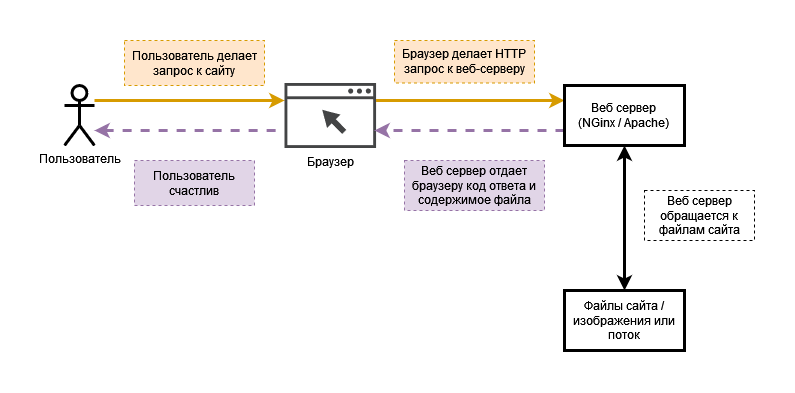
Когда хотел запилить красивую иллюстрацию, но умеешь только двигать блоки в Draw.io
Примерно так работает веб-сервер. Конечно, схема несколько упрощена, но для общего понимания вполне достаточно.
Кроме приема запросов и отдачи контента, веб-сервер формирует HTTP заголовки и коды ответа от сервера. Что это такое? Сейчас разберемся.
Что такое HTTP заголовки и какими они бывают?
Каждый HTTP запрос сопровождается служебной информацией — заголовками (headers). С помощью заголовков веб-сервер и браузер находят общий язык. Веб сервер понимает кто и к какому адресу обращается, какие данные он передает, тип запроса и многое другое. Браузер же понимает какой тип контента отдал ему веб-сервер, вес контента и прочее.
В протоколе HTTP существует четыре типа заголовков:
- General headers — основные заголовки;
- Requests headers — заголовки запроса;
- Response headers — заголовки ответа;
- Entity Headers — заголовки сущности.
Типичные HTTP заголовки запроса выглядят примерно следующий образом:

В таблице представлены только те данные, которые нам понадобятся в дальнейшем. Для более глубокого погружения в тему, советую:
Какими бывают запросы?
В протоколе HTTP предусмотрено большое количество методов с помощью которых можно совершать запросы. Но в повседневной практике используется, как правило только три: GET, POST и HEAD. Их мы и рассмотрим.

Для тех, кому интересно узнать о других методах:
Немного о кодах ответа HTTP
Каждый HTTP запрос в ответ возвращает набор данных. Среди них заголовки ответа, содержимое документа и конечно же код ответа.
При этом если методов для совершения запросов всего 9, то всевозможных кодов ответа насчитывается более 50. Мы рассмотрим коды ответов от сервера по группам.
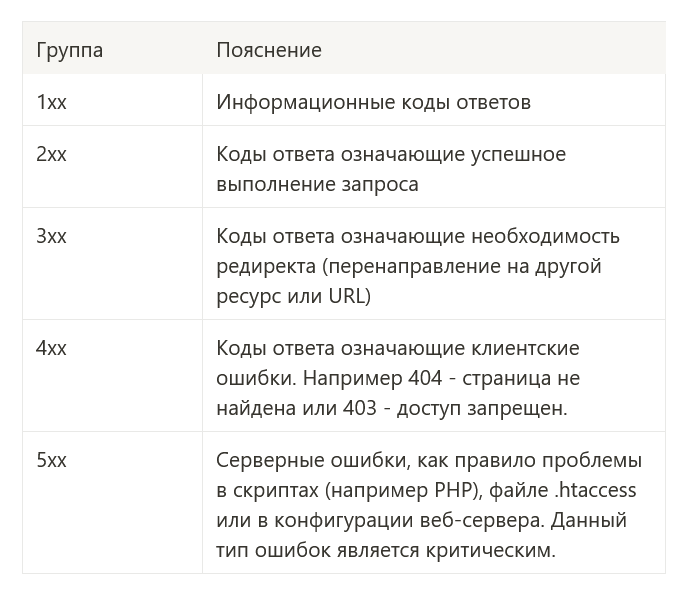
Опять таки для всех интересующихся рекомендую:
Что такое логи веб-сервера?
Говоря простым языком логи — это журнал, куда записываются все совершенные на сервер запросы. Технически логи — простые текстовые файлы. Все популярные веб-серверы имеют поддержку логов по-умолчанию. У всех хостинг-провайдеров также есть поддержка логов.
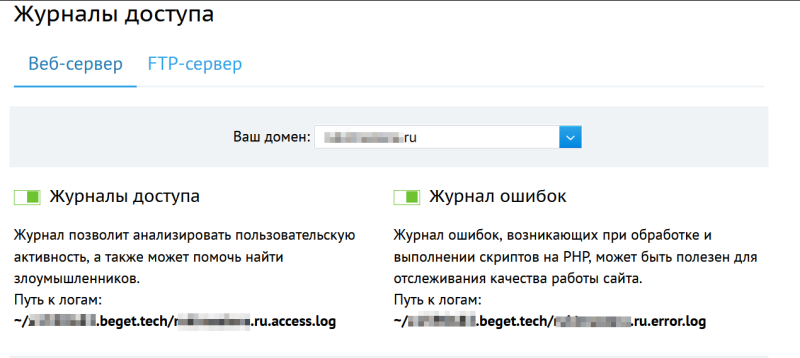
Пример для хостинг провайдера beget.com
Логи бывают двух видов: логи запросов и логи ошибок. Оставим последние для разработчиков и сосредоточимся на логах запросов.
В большинстве случаев в логах содержится следующая информация:
- IP адрес устройства с которого совершен запрос;
- URL адрес к которому направлен запрос;
- Дата и время запроса;
- Метод с помощью которого совершен запрос (GET, POST и т. д);
- Код ответа на совершенный запрос;
- Referer — адрес страницы с которой был совершен переход на текущую;
- User-Agent пользователя — идентификатор устройства и браузера.
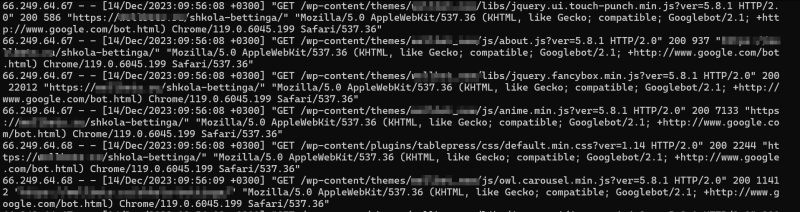
Как-то так выглядят логи NGINX на сервере
Наш краткий экскурс закончен. Теперь перейдем к главному. Зачем анализировать логи? На что стоит обратить внимание? И как делать это удобно?
Зачем анализировать логи?
С помощью логов мы можем выявить множество метрик:
- На какие страницы чаще всего заходят пользователи;
- С каких устройств чаше всего заходят пользователи;
- Какие поисковые боты посещают сайт и какие страницы индексируют;
- Наличие на сайте несуществующих страниц, к которым тем не менее обращаются пользователи и, что наиболее важно поисковые боты;
- Наличие на сайте редиректов;
- Наличие на сайте критических ошибок 5xx.
Поскольку статья написана для СЕО-специалистов, мы подробно остановимся на четырех последних пунктах, которые могут влиять на отношение поисковых систем к сайту.
Анализируем логи с помощью SEO Log File Analyser
Читать логи прямо из файла конечно можно, но нам нужно получить структурированную информацию, которую можно анализировать. Поэтому нам понадобится специальное ПО.
Для этого скачаем и установим программу SEO Log File Analyser. Её можно купить на официальном сайте, либо найти и скачать в интернете.
Главный экран программы
Теперь необходимо выгрузить логи с хостинга. В случае если у вас обычный хостинг сайта, а не VPS или выделенный сервер, то все делается через панель управления хостингом.
Например, на хостинге Beget для доступа к логам необходимо зайти в файловый менеджер. Затем в директорию с сайтом и в ней найти файл с названием типа: domain. ru. access. log.
Шаг 1. Находим и скачиваем файл. Если найти файл не удалось, то пишем в техническую поддержку.
Шаг 2. Найдя и скачав файл заходим в программу и нажимаем кнопку Import → Log file.
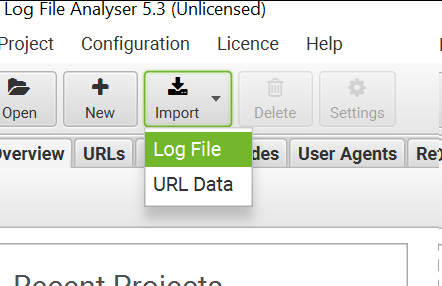
Шаг 3. В открывшемся окне выбираем загруженный файл.
Шаг 4. Задаем имя проекта и нажимаем OK.
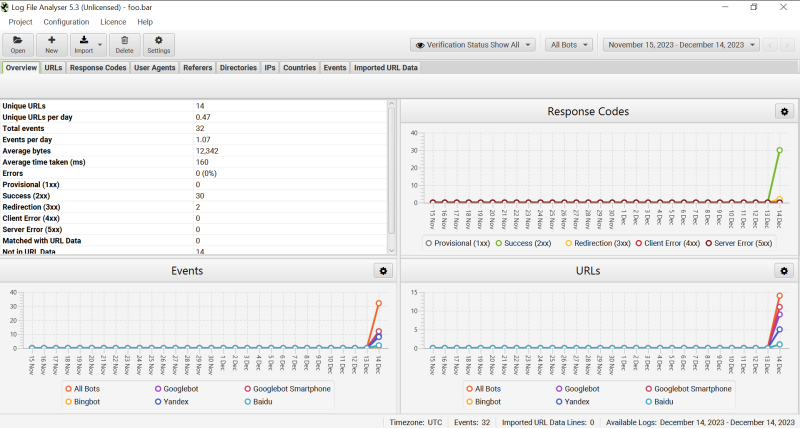
Если сделали все правильно, то увидите примерно следующее. На этом экране уже можно увидеть основные показатели. Такие как:
- Количество уникальных запросов;
- Количество запросов с группировкой по кодам ответа;
- Общее количество ошибок;
- И прочие различные графики.
На что стоит обратить внимание?
Поисковые системы совершают периодическую индексацию сайта. Они обходят его страница за страницей. Нередко на сайтах, особенно больших и особенно работающих на различных CMS, встречаются битые ссылки и страницы, которые возвращают коды ответов отличные от 2xx, т. е 3xx, 4xx, 5xx.
Поисковые системы разумеется обходят все эти страницы. Даже те, которые отдают 301, 404 и 500 коды ответов. Что, во первых, расходует определенную квоту, которая позволяет обойти N-колчество страниц за раз, а во вторых понижает качество сайта в глазах поисковой системы.
Чем больше на сайте ошибок, битых ссылок, редиректов и прочего мусора, тем ниже сайт будет ранжироваться в поисковой системе, поскольку такой сайт является низкокачественным. Это подтверждается банальной логикой и эмпирическими данными.
Исходя из этого на важны следующие показатели:
- К каким страницам обращаются роботы Google и Yandex;
- Нет ли среди этих страниц таких, которые отдают коды ответа 3xx, 4xx, 5xx;
- Нет ли в целом на сайте страниц, которые отдают коды ответов отличных от 2xx;
- Нет ли на сайте страниц, которые имеют битые URL.
Для того чтобы проанализировать их, необходимо сделать следующее:
Шаг 1. Перейти на вкладку “URLs” и выбрать там фильтр по поисковым ботам.
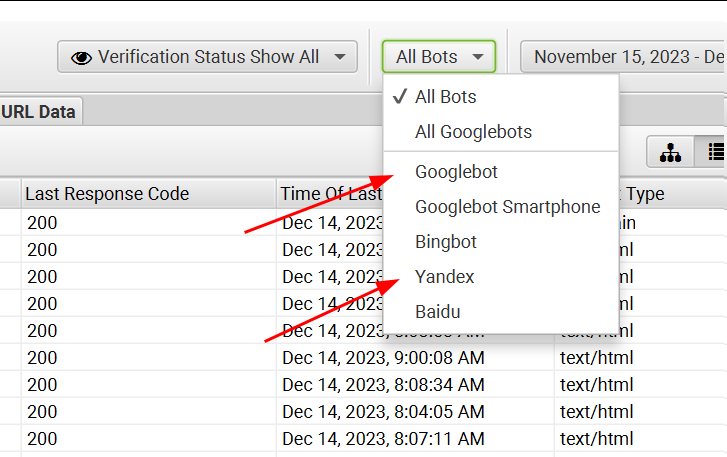
Шаг 2. Отсортировать запросы по кодом ответа.
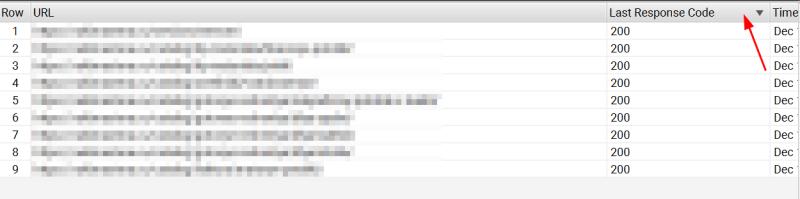
Таким образом мы сможем понять к каким страницам стучаться поисковые боты, какие страницы на сайте имеют ответы типа 301, 302, 404, 500 и другие.
Что со всем этим делать?
Если на сайте были найдены ошибки типа 404, нужно удалить со страниц сайта, а также из карты сайта все упоминания таких ссылок.
При наличие ошибок типа 500, необходимо обратиться за помощью к вашему разработчику или системному администратору, для нахождения причин и решения проблемы.
При наличие редиректов 301, 302, необходимо понять действительно ли они вам необходимы. Возможно, вам было лень менять ссылку со старого раздела на новый и вы решили поставить редирект. Разумеется так лучше не делать и заменить старую ссылку на новую, а старый раздел и вовсе удалить.
Мониторинг логов в реальном времени
Для серьезных проектов, где очень важна отказоустойчивость сайта, необходим мониторинг логов в реальном времени. Для этого существует ряд решений, который устанавливается на сервер. Например, к ним относится: Zabbix, Grafana и другие системы мониторинга.
Для личных проектов я разработал свое решение — https://github. com/dbkv9/tglog. Исходные тексты проекта доступны без каких либо ограничений под лицензией MIT.
Программа устанавливается на сервер под управлением Linux и умеет анализировать логи в реальном времени. При обнаружение ошибок, она сразу же сообщает об это в Telegram, через Telegram бота.
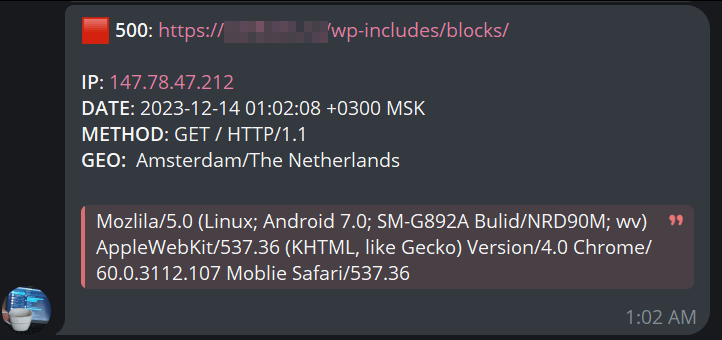
Кроме прочего бот позволяет экспортировать лог в формате Excel.
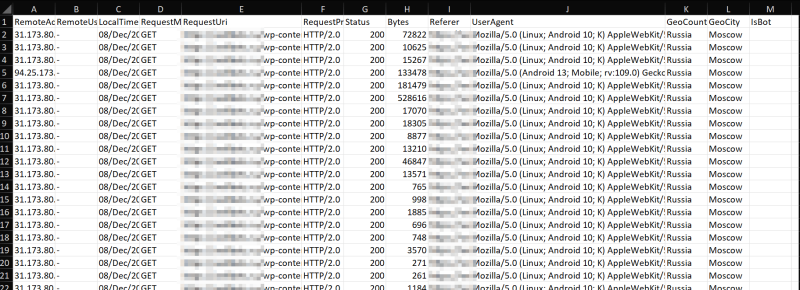
Инструкция по развертыванию есть в репозитории на Github. В текущей версии поддерживается только NGinx, но в планах добавить поддержку Apache и много других плюшек.
35 показов 18 открытий
Monstro – сервис для продвижения сайтов и услуг
https://t.me/monstrotraf