На связи команда сервиса ARSENKIN TOOLS и мы с новостями обновления нашего одного из популярных инструментов «Кластеризатор». Кластеризация – это автоматическая разбивка ключевых фраз на группы.
Что нового
Мы решили текущий инструмент кластеризации поделить на разные методы и вывода данных:
- Экспресс кластеризация
- Группировка больших ядер
- Группировка на своих данных
Экспресс кластеризация
Экспресс кластеризация – позволит выполнить группировку по методу HARD и вывести весь результат группировки в веб интерфейс.
Обычно такой метод позволяет быстро проверить небольшую группу запросов без выгрузки Excel файла.

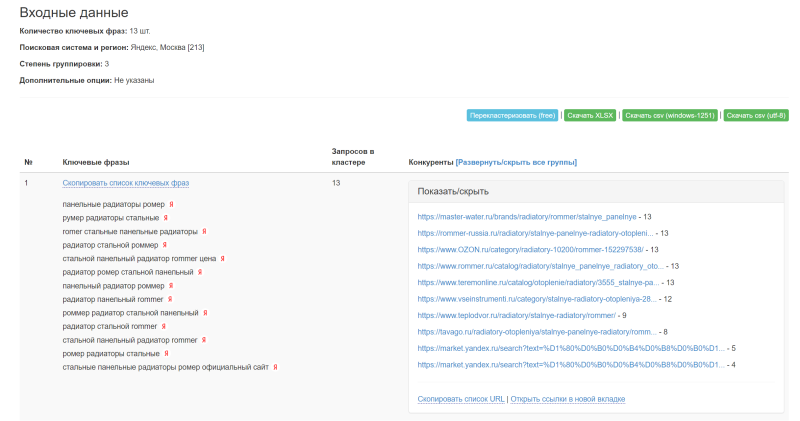
Веб-интерфейс результата при методе экспресс-кластеризация
Особенности
- Количество ключевых фраз на входе: от 2 до 300, даже на максимальных тарифах.
- Группировка фраз происходит по методике HARD и глубина парсинга ТОП-10.
- В результатах без проблем можно: 1) Скопировать список ключевых фраз группы; 2) Кликнуть на иконку Яндекса или Google и посмотреть выдачу самому; 3) Скопировать список URL группы; 4) Открыть в новой вкладке все 10 URL в браузере одним кликом.
- Есть опция перегруппировки с возможностью изменения степени группировки. Опция бесплатная и дополнительные лимиты не списываются.
- Можно скачать результаты в привычный Excel файл и далее крутить информацию как вам необходимо.
Группировка больших ядер
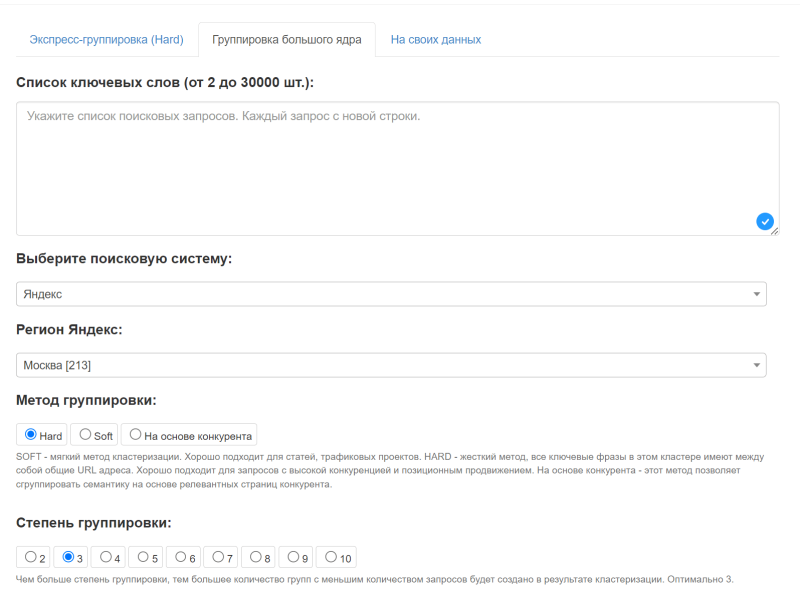
Группировка больших ядер – метод, который позволит делать группировку большого семантического ядра. На текущий момент в интерфейсе вы можете указать до 30 000 ключевых фраз (индивидуально можем обработать более 100 000 ключевых фраз).
Особенности:
- Список ключевых слов: от 2 до 30 000 фраз
- Методы группировки: Hard, Soft и наш новый метод группировки
«На основе конкурента» (подробнее чуть ниже)
- Глубина парсинга ТОП на выбор от 10 до 30.
- Дополнительные параметры: сбор всех видов частотности из Яндекс Вордстат, исключение доменов и главных страниц.

В этом методе всё как обычно, ничего нового не добавилось.
Новый метод группировки «На основе конкурента»
Этот метод позволяет сгруппировать семантическое ядро на основе релевантных страниц конкурента. ВАЖНО, правильно подобрать конкурента с хорошей структурой.
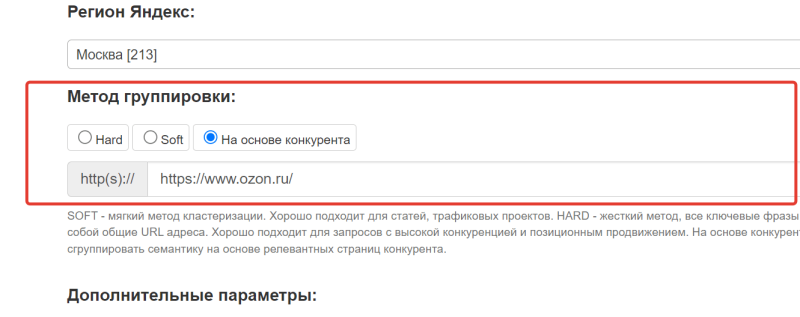
Метод группировки «На основе конкурента»
Схема простая: наша система делает запросы к поисковой выдаче в формате [ключевая фраза site:domain.com] и забираем первый URL адрес. Далее ключевые фразы группируем на основе одинаковых URL.
Результат работы инструмента можно будет скачать в Excel и файл будет содержать следующую информацию (запросы, название группы, топоним в запросе, URL адрес вашего конкурента, на основе которой делалась группировка, в будущем добавим пробивки своих релевантных страниц):
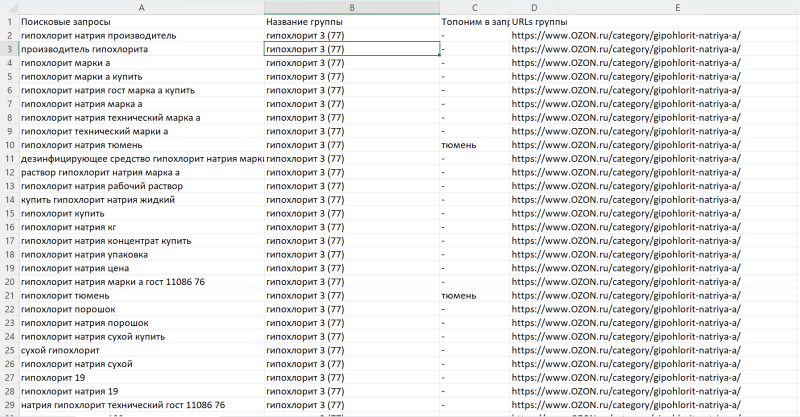
Результат файла по методике «На основе конкурента»
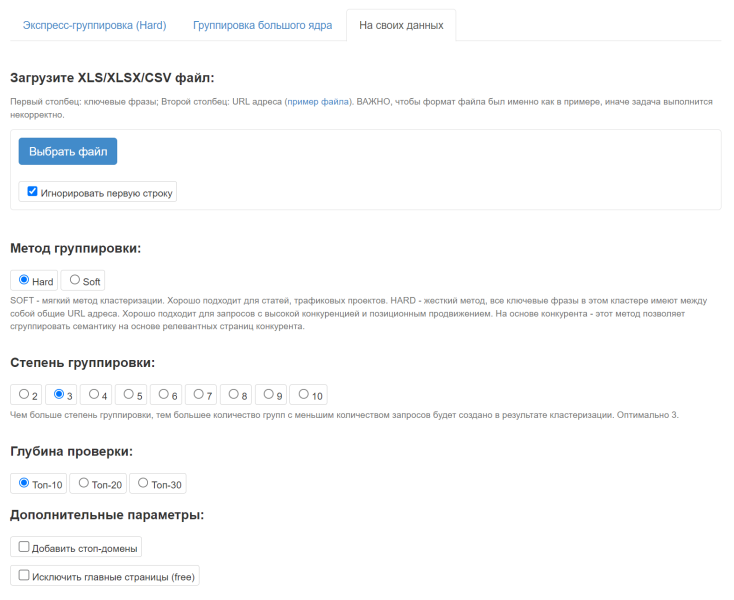
Группировка на своих данных
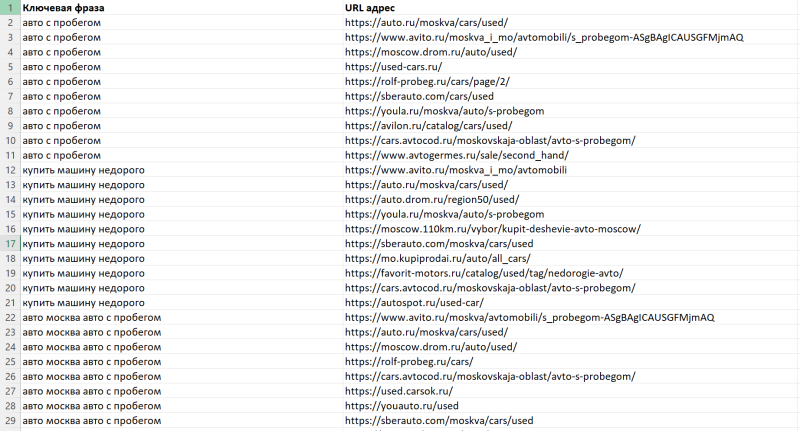
Группировка на своих данных – это метод группировки, где вы сами загружаете ключевые фразы и URL адреса из ТОП поисковой выдачи для дальнейшей группировки.
Входной файл должен выглядеть следующим образом:
Требования к файлу и процесс загрузки:
- Файлы формата xlsx, xls и csv (разделитель точка запятая).
- Не более 5 000 000 строк (в будущем будем расширять кол-во строк)
- Файл размером не более 200 мб.
- Файл может загружаться более 3 минут, всё зависит от размера файла.
- После загрузки происходит разбор файла и подсчёт количества фраз и URL (подсветится зеленым цветом). Только после этого можно будет запустить задачу.
ЗА выполнение 1 задачи будет списано 100 лимитов.
—-
Коротко пробежались по обновлениям инструмента по кластеризации поисковых запросов.
71 показ 27 открытий
Monstro – сервис для продвижения сайтов и услуг
https://t.me/monstrotraf